Topic 2b: Mathematical Operations in Numpy
Contents
Topic 2b: Mathematical Operations in Numpy#
Numpy has a lot of built in flexibility when it comes to doing math. The most obvious thing you might want to do is to treat numpy arrays as matrixes or vectors, depending on the circumstance. The recommend way to do this is to use the functions that specify vector multiplication:
import numpy as np
A = np.linspace(1,9,9)
B=A.reshape((3,3))
print(B)
print(B*B) # elementwise multiplication
[[1. 2. 3.]
[4. 5. 6.]
[7. 8. 9.]]
[[ 1. 4. 9.]
[16. 25. 36.]
[49. 64. 81.]]
print(np.dot(B,B)) #matix multiplication
[[ 30. 36. 42.]
[ 66. 81. 96.]
[102. 126. 150.]]
print(np.dot(A,A)) # vector dot product
285.0
print(np.dot(np.array((1,2,3)),B)) # left multiplication
[30. 36. 42.]
print(np.dot(B,np.array((1,2,3)))) # right multiplication
[14. 32. 50.]
C=B+np.identity(3) # matrix addition acts as usual
print C print np.linalg.inv(C) # matrix inverse
np.dot(C,np.linalg.inv(C))
array([[ 1.00000000e+00, -2.22044605e-16, 4.44089210e-16],
[-1.77635684e-15, 1.00000000e+00, 8.88178420e-16],
[-1.77635684e-15, 4.44089210e-16, 1.00000000e+00]])
Random Numbers#
Generating random numbers is an extremely useful tool in scientific computing. We will see some applications in a second, but first let’s just get the syntax.
The first thing you might want is a random number drawn from a uniform probability between 0 and 1
np.random.rand()
0.5702650120489982
This function actually will give you a bunch of random numbers in any shape
np.random.rand(10)
array([0.76960135, 0.0107838 , 0.76580124, 0.02474949, 0.56232733,
0.85697842, 0.8916609 , 0.17639742, 0.74292747, 0.91188133])
np.random.rand(2,2,2)
array([[[0.92197513, 0.61219907],
[0.4798353 , 0.49352586]],
[[0.02276897, 0.21042061],
[0.4032398 , 0.18652249]]])
Given such a distribution, we can make our own function to cover any uniform distibution:
def my_uniform(low,high,number):
out=np.random.rand(number)
out*=(high-low)
out+=low
return out
my_uniform(10,11,20)
array([10.01239268, 10.67553379, 10.87863373, 10.86319778, 10.40457733,
10.90734644, 10.26383446, 10.18433965, 10.9974468 , 10.37957655,
10.14480237, 10.75097067, 10.28721474, 10.11358887, 10.07274411,
10.27626553, 10.38016954, 10.97938739, 10.12854462, 10.22090279])
my_uniform(-102.3,99.2,20)
array([ 75.9230459 , 7.83149466, -19.45311926, -47.64907301,
18.0997908 , 43.95968584, 46.06523206, 18.7915172 ,
-84.52666947, -47.27590603, -68.6559249 , 78.41502161,
26.46698118, -100.13169015, 93.74563134, 28.03872602,
-8.62756594, -19.62638069, 67.61582995, -96.86394862])
naturally, numpy has its own version of this function
np.random.uniform(-102.3,99.2,20)
array([ 2.16444471e-02, 7.14131481e+01, 9.48559531e+01, 1.35034127e+01,
3.76437953e+01, 7.47067648e+01, 8.73765236e+01, 4.61136276e+01,
-2.83950517e+01, 8.31007553e+01, -1.29846479e+01, -9.78728496e+01,
4.10922617e+01, -9.55774106e+01, -6.30585410e+01, 6.59048284e+01,
8.80143455e+01, 8.68401949e+01, -5.51825416e+01, -6.33892118e+01])
However, it is important to realize that once you have a source of random numbers, you can mold it to do other things you want
The other common kind of random number you will want is one drawn from a normal distibution. This means the probability (density) of drawing the number x is \(P(x) = e^{-(x-\mu)^2/2\sigma^2}/\sqrt{2\pi \sigma^2}\). The number \(\mu\) is called the mean and \(\sigma\) is the variance.
Python has a nice way of generating numbers with \(\mu =0\) and \(\sigma=1\):
np.random.randn(10)
array([ 1.22590292, -0.64590733, 0.01596462, -1.79777083, 0.20012987,
-0.37714249, -0.42078726, 1.20704924, -1.23151118, -0.80821818])
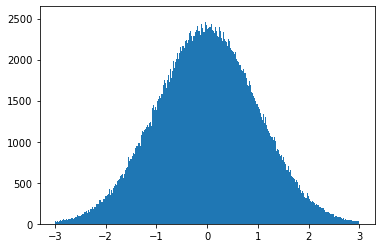
Let’s make a histogram to see what this is doing:
import matplotlib.pyplot as plt
plt.hist(np.random.randn(1000000),bins=np.linspace(-3,3,1000))
plt.show()
np.random.randint(3,size=100)
array([0, 0, 2, 2, 0, 2, 1, 1, 2, 0, 1, 2, 0, 0, 2, 0, 1, 0, 0, 1, 2, 2,
0, 0, 1, 0, 2, 1, 2, 2, 0, 1, 1, 1, 2, 1, 0, 1, 0, 2, 1, 1, 1, 2,
2, 2, 1, 0, 2, 2, 2, 2, 2, 0, 2, 1, 2, 2, 2, 0, 2, 0, 1, 0, 1, 2,
2, 0, 1, 1, 0, 2, 2, 1, 1, 1, 2, 1, 2, 1, 0, 1, 0, 1, 2, 2, 0, 0,
1, 1, 2, 0, 0, 2, 0, 1, 2, 1, 1, 1])
np.random.randint(2,size=10).sum()
3
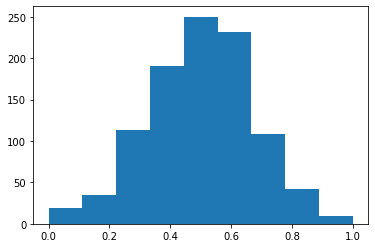
number_of_flips=10
number_of_trails=1000
results=np.zeros(number_of_trails)
for i in range(number_of_trails):
results[i]=np.random.randint(2,size=number_of_flips).sum()/float(number_of_flips)
plt.hist(results,bins=np.linspace(0,1,10))
plt.show()
Demonstration: calculating \(\pi\)#
To get a quick sense of why this is useful, we can demonstrate how we can calculate \(\pi\) using what we have just learned. This will actually serve as an important example of a much broader and more powerful set of techniques later in the course, but for now it is just to give you a taste of how these things can work for you.
The idea is the following: image you pick a point randomly inside a square of length 2 on each side. The area of this square is 4. I circle placed within the square with radius 1 has area \(\pi\). If a random draw numbers that land inside the square with a uniform probability, then \(\pi/4\) of them (on average) should also be inside the circle. Said different, after picking a point in the square, we ask if it is also in the circle and keep track. At the end we take number in circle / total we have caculated \(\pi/4\)
def pi_calculator(N):
x=np.random.uniform(-1,1,N) # make a list of N random numbers of x-axis of box
y=np.random.uniform(-1,1,N) # make a list of N random numbers of y-axis of box
z=(x**2+y**2<1) # make a list of every time x^2 + y^2 < 1 (inside the cicle)
return z.sum()/float(N)*4 # add all the points in the circle up and return 4*cicle/N
pi_calculator(10**7)
3.1411488
pi_calculator(10**8)
3.14164224
pi_calculator(10**9)
x=np.random.uniform(-1,1,5)
y=np.random.uniform(-1,1,5)
z=(x**2+y**2<1)
print(x,y)
print(x**2+y**2)
print(z)
[-0.46261577 0.93124438 0.74169432 0.45117097 0.1718111 ] [ 0.89592606 0.11286007 -0.40097035 0.9466685 -0.91434233]
[1.01669686 0.87995349 0.71088768 1.09973649 0.86554094]
[False True True False True]
z.sum()
3
To see how this is working, let’s write a slower version to see the steps
def pi_slow(N):
circle=0
for i in range(N):
x=np.random.uniform(-1,1,1) # pick a x coordinate in the box
y=np.random.uniform(-1,1,1) # pick a y coordinate in the box
if x**2+y**2<1: # make a list of every time x^2 + y^2 < 1 (inside the cicle)
circle+=1
return 4*circle/N # add all the points in the circle up and return 4*cicle/N
pi_slow(10**6)
3.14284
pi_calculator(10**8)
3.14165004
The slow implementation makes it clear what we are doing, but it clearly takes much longer.
import time
t1 = time.time()
pi_slow(1000000)
print(time.time() - t1)
9.319647073745728
t1 = time.time()
pi_calculator(1000000)
print(time.time() - t1)
0.0646061897277832
Anticipating something we will discuss later, now let’s see how our error in the measurement of pi scales with the number of random points we pick
short=int(10**6)
medium=int(10**7)
Long=int(10**(8))
trials=100
pi_list_short=np.zeros(trials)
pi_list_medium=np.zeros(trials)
pi_list_Long=np.zeros(trials)
for i in range(trials):
pi_list_short[i]=pi_calculator(short)
pi_list_medium[i]=pi_calculator(medium)
pi_list_Long[i]=pi_calculator(Long)
fig, ax = plt.subplots()
p1=ax.hist(pi_list_short,bins=np.linspace(3.13,3.15,100),label='$10^6$')
p2=ax.hist(pi_list_medium,bins=np.linspace(3.13,3.15,100),label='$10^7$')
p3=ax.hist(pi_list_Long,bins=np.linspace(3.13,3.15,100),label='$10^8$')
ax.plot([np.pi,np.pi],[0,40])
plt.ylim(0,40)
plt.xlim(3.1375,3.145)
leg = ax.legend()
plt.show()
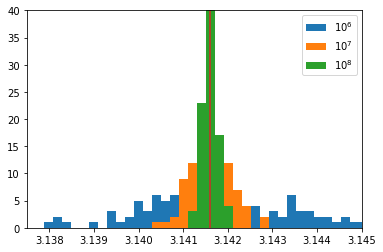
By eye, it looks like the blue is a approximately 10 times wider than the green. This would make sense if the error on the value of \(\pi\) decreased by \(1/\sqrt{N}\) where \(N\) is the number of random points used in the calculation. This is indeed what is going on and is a much more general fact about random numbers.
Summary#
Numpy has a number of basic math operations we will make a lot of use off. Random numbers are a particularly valuable tool that is employed in all areas of science and engineering. E.g. simulating the behavior of any measurement involves adding random numbers to you signal. We can always use the output of the random number library to create the type of noise we want for a given application.