Topic 5: Intro to Data Analysis
Contents
Topic 5: Intro to Data Analysis#
Understanding and visulizing data is a central problem in the sciences and beyond. We will begin with the very basics and we will return to discuss more advanced methods later in the course.
The starting point for most data analysis is literally reading in the data so that you can use it in python.
import numpy as np
import matplotlib.pyplot as plt
Here is how we open a generic text file. We will print all the lines so you can see what the file looks line
f=open("data1.txt","r") # "r" means we are reading the file
for line in f:
print(line)
f.close()
# here is some preamble
# here is some more preamble
1.0,-0.6311688938249904,0.45488424301397556,1.4166838803401072,
1.0909090909090908,0.1836650127781727,-1.2320204754180588,1.4640662255632122,
1.1818181818181819,-1.2067884002340479,-0.9383912321268246,-1.4714065565433299,
1.2727272727272727,-0.07397985995933759,1.8395768409168949,-0.0796575263423811,
1.3636363636363638,-0.737654908251103,-1.2826141566048304,2.143318426612972,
1.4545454545454546,-0.6352094090520055,1.196605783495026,-0.5272364016024303,
1.5454545454545454,-1.3478569367857853,1.2726038119049938,-0.2387464313240688,
1.6363636363636362,1.7643027277060235,-1.3358815620673254,0.42002797035543593,
1.7272727272727273,1.1228898074019433,0.4373429207381663,-0.1053287323238627,
1.8181818181818183,-1.9235573265400396,1.0784356569475517,-0.43585645156397873,
1.9090909090909092,-2.5203822814363916,0.2925419990496477,-0.7175310482674775,
2.0,-0.20414929117298058,1.8548073032642414,-1.6689147413533778,
2.090909090909091,0.6621809483393832,-0.3051219239294479,1.1131763474375251,
2.1818181818181817,0.3182087214669058,-0.042937245099687604,1.1752070761056175,
2.2727272727272725,0.22912356066614792,0.29073506428594337,1.7818860311483344,
2.3636363636363638,-0.3829663239804597,1.2152670827311336,-0.47144795060521066,
2.4545454545454546,1.865932067710966,0.7675499181699784,0.12187118234859495,
2.5454545454545454,-0.08836032079560019,-0.1666437043109095,0.626776483177752,
2.6363636363636367,-0.1157667893960524,0.4901440432726023,0.4253528301358699,
2.7272727272727275,0.24497585695544113,2.7752811189421585,0.343931167436819,
2.8181818181818183,0.14888310641784397,0.9543988718029668,0.8880236302997588,
2.909090909090909,-0.2114497883523676,-1.688434540970014,0.27935921952965387,
3.0,1.0352247792742475,-1.0731955421188029,2.701509689543154,
3.090909090909091,-0.8537914813011567,1.7509227026567182,-0.9552216026515601,
3.1818181818181817,1.3722857219464086,-0.37647616008459883,-0.16025010581716082,
3.272727272727273,0.053927881477298795,-1.3127359490133514,2.711507312349479,
3.3636363636363638,-0.4068758845366948,0.7035038827738344,0.30365742503758647,
3.4545454545454546,-0.44478474721640066,-1.4555517678140941,2.3713902873526815,
3.5454545454545454,2.116426641034081,1.0109175166041757,1.7765903267105174,
3.6363636363636362,0.11636504326654121,-0.39359214869578835,2.032829663570117,
3.7272727272727275,0.8015329178643593,0.7273604384719508,1.227679834941189,
3.8181818181818183,0.6456429398866661,-1.352494638078151,3.1188298852583616,
3.909090909090909,1.613784466354094,0.04898448107888345,2.708345137790178,
4.0,-1.41366205041043,1.0229177097053903,1.5199421945650475,
4.090909090909091,-0.3421580136252812,-1.1187303130674546,0.7096631263875519,
4.181818181818182,0.07888321542058939,0.8636770901568209,1.2864962209751158,
4.272727272727273,1.8760741154369092,-1.3073459162098775,2.588484416332107,
4.363636363636363,0.06585764882180982,0.8705697000713934,2.124660688963388,
4.454545454545455,-0.22438214432973524,0.4027602740454191,3.066047039885218,
4.545454545454545,-2.0491518156959208,0.9922030057065043,1.4647428779952012,
4.636363636363637,0.5823994686118554,1.4178740616537855,1.1659646426268564,
4.7272727272727275,1.1174069972630207,-0.04600732058846052,2.5796909818035645,
4.818181818181818,-1.179141881111505,3.2015700262839704,0.07426732300802663,
4.909090909090909,-0.5685640147773101,0.8422491785269339,1.9361054483673024,
5.0,0.49560619172623754,1.378808545961349,2.772330131342585,
5.090909090909091,0.24585784653847198,-0.20555502242005147,1.131185156172839,
5.181818181818182,1.5643862123074455,-0.11958099935101546,1.3147100878015254,
5.2727272727272725,-1.1151867423383657,0.5168985098872407,3.1046733325611573,
5.363636363636363,-0.2726364668908259,-0.08699783939484457,3.2585070783888552,
5.454545454545455,0.9001532285209066,1.3526696413293455,1.8728542161334232,
5.545454545454546,-0.6202357596001613,2.007273180695664,1.2825433316035202,
5.636363636363637,1.1819882134237294,-0.22142023759539192,2.365387520829122,
5.7272727272727275,-0.5941962918244037,-0.14320348032695024,2.6040454782634064,
5.818181818181818,-0.02477118308961286,0.9716562819146767,2.148810432530392,
5.909090909090909,0.8327767577068002,-0.2927110377652543,3.069936739485766,
6.0,-1.1556411055077778,1.4417724412287023,3.1886656103478708,
6.090909090909091,-1.2168552986118735,0.4506696001559499,2.386898651226657,
6.181818181818182,-0.6157921010281806,-0.497108647756321,0.05661589728718264,
6.2727272727272725,-1.7671583367295978,1.135331434196452,2.817105149730652,
6.363636363636364,0.13096635693994016,-0.22052459096032073,3.160826314988174,
6.454545454545455,0.690294866968097,1.8963277920971895,4.487425364155156,
6.545454545454546,2.371694887897769,0.27960637363250584,2.3644192911897908,
6.636363636363637,1.273825402614828,0.8687499947091604,3.305655085108792,
6.7272727272727275,0.37967675226481273,-1.3159423011413678,1.661604297176963,
6.818181818181818,1.0948910337870426,1.3123807007747081,3.6798167626896023,
6.909090909090909,-1.6205454405798412,2.9248119763275087,2.3917854722312857,
7.0,0.735428855084481,1.7767204644281096,3.3694488806819884,
7.090909090909091,-0.04455145140604422,-0.1371341937628388,2.642018658136439,
7.181818181818182,-1.5357456259373374,1.604807734797527,4.412411518091927,
7.2727272727272725,-2.009658212034761,-0.7726057755922854,4.155582143990508,
7.363636363636364,2.374179182366948,1.0793284192789065,3.170149680288414,
7.454545454545455,-0.6902691820562796,0.3217260254744907,2.865907753457373,
7.545454545454546,-0.15763329565736972,-0.2569440439920063,3.368592679754569,
7.636363636363637,0.9242345372372889,0.27667266297441834,3.637880473686003,
7.7272727272727275,-3.1875997601455275,2.199806115530024,2.1096391833912675,
7.818181818181818,-1.1718948899473165,0.10319898990813686,4.576445271388832,
7.909090909090909,0.9785580968322369,0.009469202542572108,4.49391127399047,
8.0,-0.8665677410547212,-0.17314343767459317,5.313216187997888,
8.09090909090909,-1.6213716879341697,1.1684574860898165,3.19369658313685,
8.181818181818182,-0.06367514456694123,1.4356964984967884,5.912587734389751,
8.272727272727273,0.7401111090339849,0.43828138891593493,4.616231505466975,
8.363636363636363,1.446697225209474,0.2686299890785137,6.166373213464694,
8.454545454545455,2.0171465823853088,1.7122578969698194,4.543006941829624,
8.545454545454547,0.05547192247442552,-0.6291651473329716,4.507974800623014,
8.636363636363637,-0.0197020770305536,0.9233026597415765,6.920201295831565,
8.727272727272727,-0.4911129241676753,1.6061208531128814,3.8010877096815032,
8.818181818181818,2.069890341411209,-0.209459536509214,6.761139952443798,
8.90909090909091,0.032529746059397326,-1.754907126230721,5.2962287556147905,
9.0,1.4366854455763804,-0.9398701401824869,6.13375599845889,
9.090909090909092,-1.0881560738374398,0.7241679159272209,7.010425652001209,
9.181818181818182,0.4358544140396277,0.2484598305057409,4.543475541105149,
9.272727272727273,0.47595695530935767,1.8022691191471243,5.451213213875634,
9.363636363636363,0.6720375552319127,2.6861025069373134,7.9347242752625275,
9.454545454545455,0.15566217413846836,0.9488508609031605,5.960063077396186,
9.545454545454545,0.5227159219087347,-0.20599329826767998,7.820105590320214,
9.636363636363637,-0.23146925909689864,0.6207016561335794,5.959715623500961,
9.727272727272727,-0.5167395516639268,0.7343253426310082,5.3781930296290685,
9.818181818181818,-0.005145926712907867,1.8884676984294115,6.645049022367959,
9.90909090909091,2.167391340402733,1.8142239879060225,6.244150828030593,
10.0,0.7589063994652221,-0.4915403755397779,8.432902602792572,
Reading the 3rd line we see that the data is organized as time,data,data,data. Our goal is to read in this data. We need to do two things: (1) we also want to skip over the preamble that starts with #. (2)we want to save the data into 4 arrays, one for the time and 3 others for the time series data. Here is how we can do it. First, we notice there is a nice command
txt1='#preamble'
txt2='data'
print(txt1.startswith('#'),txt2.startswith('#'))
True False
Second we notice that we can split a string into pieces as follows:
string1='Welcome to UC San Diego'
string2='comma,separated,words'
print(string1.split())
print(string2.split())
print(string2.split(','))
print(string2.split(',')[2],string2.split(',')[1])
['Welcome', 'to', 'UC', 'San', 'Diego']
['comma,separated,words']
['comma', 'separated', 'words']
words separated
Using split(), we can isolate particular pieces from a given line in the file. Putting these together we can load the data as
t_temp=[]
l1_temp=[]
l2_temp=[]
l3_temp=[]
f=open("data1.txt","r") # "r" means we are reading the file
for line in f:
if line.startswith('#')==False:
spl=line.split(',')
t_temp.append(float(spl[0]))
l1_temp.append(float(spl[1]))
l2_temp.append(float(spl[2]))
l3_temp.append(float(spl[3]))
f.close()
t=np.array(t_temp)
d1=np.array(l1_temp)
d2=np.array(l2_temp)
d3=np.array(l3_temp)
plt.scatter(t,d1)
plt.scatter(t,d2)
plt.scatter(t,d3)
plt.show()
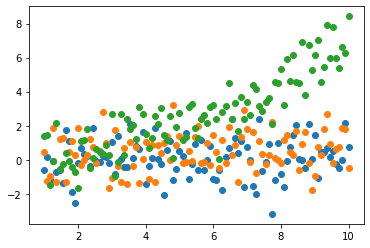
We have successfully loaded our data and made a quick plot to see that it makes sense. It certainly looks like some data, but what do we do with it?
Signal and Noise#
The central idea in most basic analyses is that our data can be thought of as the sum of two pieces
\({\rm data} = {\rm signal}+{\rm noise}\)
The signal is typically deterministic: in this case, it is some specific function of time that we are trying to measure.
The noise is random: it is usually assumed to be uncorrelated between bins and drawn from a Gaussian with zero mean. I.e. it is a random number drawn from a distribution that is added to our answer, but whose average is zero.
To see why this is important, let us assume that our signal is just a constant: \({\rm signal}(t) = S\) and our noise is drawn from a Gaussian distribution with variance \(\sigma\). Suppose our data is composed of \(N\) measurements. What we notice is that is we write $\(\sum ({\rm data}- {\rm signal}) = \sum {\rm noise}\)\( The right hand side is a random walk just like we did earlier in the course. We expect that average size of the RHS is set by the RMS distance of a random walk, \)\sqrt{N}\sigma\(. On the other hand \)\sum {\rm signal} = N S\(, so as we take more data our signal will stand out, even if \)S \ll \sigma$.
We can see how this works by simulating some data
def time_data(N,sigma=1,S=0.1):
return np.ones(N)*S+np.random.randn(N)*sigma
Sdata=time_data(1000)
noSdata=time_data(1000,S=0)
plt.plot(Sdata)
plt.plot(noSdata)
[<matplotlib.lines.Line2D at 0x119ce45e0>]
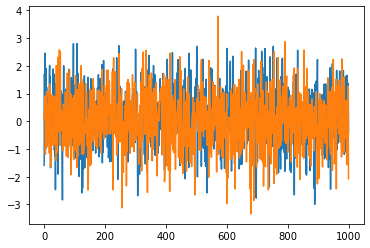
Sdata.sum(),noSdata.sum()
(130.10719365738598, 29.400606056747208)
We get a bigger answer for the case with \(S=0.1\) even though they look identical on the time series. Let’s check this isn’t an accident
S_list=[]
noS_list=[]
for i in range(1000):
S_list.append(time_data(1000).sum())
noS_list.append(time_data(1000,S=0).sum())
fig_h,ax_h=plt.subplots(figsize=(12,6))
ax_h.hist(S_list,bins=20)
ax_h.hist(noS_list,bins=20)
plt.show()
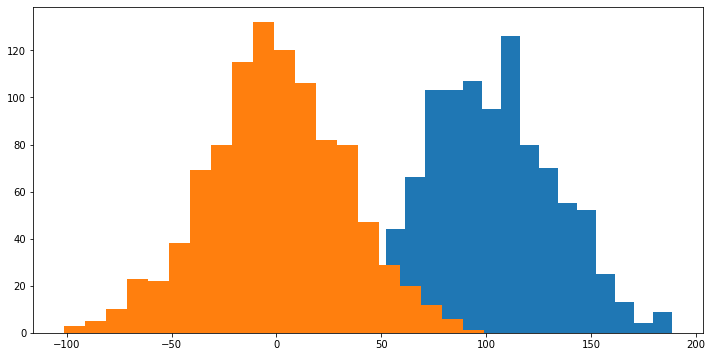
We see that there is a clear difference between the two distributions. We can repeat it with more points to see that this difference becomes more pronounced. If we make it 10000 data points, we should expect the \(S=0.1\) distribution to move to around 1000, while the \(S=0\) will be rought between -100 and 100 at 1\(\sigma\).
Sdata=time_data(10000)
noSdata=time_data(10000,S=0)
plt.plot(Sdata)
plt.plot(noSdata)
[<matplotlib.lines.Line2D at 0x11a1e1b50>]
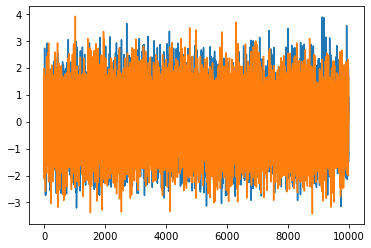
S_Llist=[]
noS_Llist=[]
for i in range(1000):
S_Llist.append(time_data(10000).sum())
noS_Llist.append(time_data(10000,S=0).sum())
fig_h,ax_h=plt.subplots(figsize=(12,6))
ax_h.hist(S_Llist,bins=20)
ax_h.hist(noS_Llist,bins=20)
plt.show()
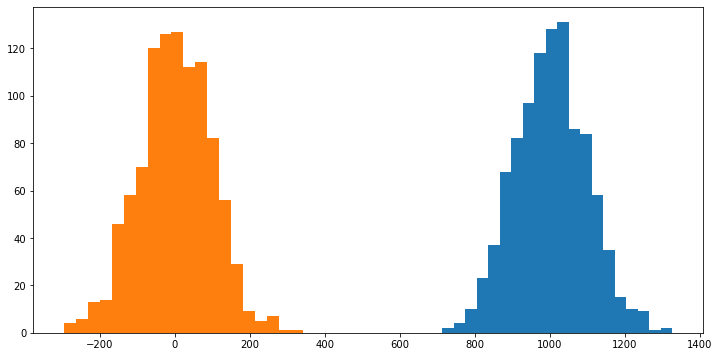
Now suppose we want to measure the value of \(S\) in our data. Suppose the true value of \(S\) is \(S_0\). Let’s just try to guess a value of \(S\) and calculate
\( \sum ({\rm data}-S)^2 = \sum (S_0+{\rm noise} - S)^2\)
Now notice that the sum over \(N\) is just \(N\) times the average, so as we take \(N\) to be large, this is just \(N\) times the statistical average. This is useful because we know the statistical properties of the noise:
\(\sum (S_0+{\rm noise} - S)^2 = N(S_0-S)^2 + N \sigma^2\)
Notice that this is the sum of two positive terms and the answer is minimized when \(S=S_0\).
So let’s see how accurate a measure of \(S\) we can make by just minimizing this quantity. I happen to know that the noise has \(\sigma=1\) so this quantity is equivalent to \(\chi^2\) (otherwise it would be \(\sigma^2 \times \chi^2\)).
data_ref=time_data(10000)
def chisqr(S):
return ((data_ref-S)**2).sum()
Srange=np.linspace(-1,1,100)
chi_out=np.zeros(len(Srange))
for i in range(len(Srange)):
chi_out[i]=chisqr(Srange[i])
plt.plot(Srange,chi_out)
[<matplotlib.lines.Line2D at 0x11ab65160>]
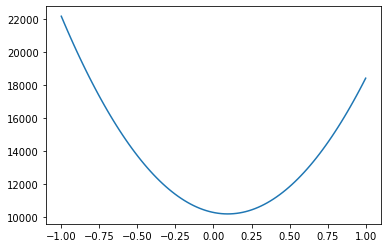
Given what we know about equation solving, we could find this minimum ourselves. However, finding minimima or maxima rapidly becomes a hard problem, so we are going to make our life easier by using a built in minimization tool:
from scipy.optimize import minimize
minimize(chisqr,0.4)
fun: 10192.994862259602
hess_inv: array([[1.32507178e-05]])
jac: array([0.00012207])
message: 'Desired error not necessarily achieved due to precision loss.'
nfev: 10
nit: 2
njev: 5
status: 2
success: False
x: array([0.09375115])
data_ref2=time_data(10000,S=0)
minimize(lambda x:((data_ref2-x)**2).sum(),0.4)
fun: 9951.489423144052
hess_inv: array([[5.e-05]])
jac: array([0.])
message: 'Optimization terminated successfully.'
nfev: 8
nit: 2
njev: 4
status: 0
success: True
x: array([0.01305158])
Minimize works more or less like our Newton solver (at this level): it takes a function and an initial point and finds a nearby point where the function is minimized (presumably where the derivative vanishes).
Using this insight, we see that minimizing this function does a pretty good job of finding the correct value of \(S\). When we put in \(S_0=0.1\) we measured \(S=0.0916426\) and when we put \(S_0=0\) we measured \(S=0.02035976\). In a future class, we will talk about how to give this measurements error-bars.
Linear Regression#
The natural next step is to fit a line to the data that we uploaded from a file. This is a thing one typically does as a first guess given data that we don’t totally understand: a line has enough freedom to capture some overall behavior, but is sufficiently simple that we aren’t going to overfit (i.e. the function is just finding patterns in the noise).
There are lots of build in functions that will give you a best fit line. For example:
from scipy import stats
slope1, intercept1, r_value1, p_value1, std_err1 = stats.linregress(t,d1)
print(slope1, intercept1, r_value1, p_value1, std_err1)
stats.linregress(t,d1)
0.044053980142284774 -0.17318253969528752 0.10331235714633374 0.30636705556359395 0.04284396708900212
LinregressResult(slope=0.044053980142284774, intercept=-0.17318253969528752, rvalue=0.10331235714633374, pvalue=0.30636705556359395, stderr=0.04284396708900212, intercept_stderr=0.26108947495494694)
slope2, intercept2, r_value2, p_value2, std_err2 = stats.linregress(t,d2)
slope3, intercept3, r_value3, p_value3, std_err3 = stats.linregress(t,d3)
What most such algorithms are doing is the same as what we did above, but now where we assume that
\({\rm data} = a t + b + {\rm noise}\)
where \(t\) is time, \(a\) and \(b\) are constants. Following what we did before, you guess that if you calculate
\(\sum ({\rm data}-a t - b)^2\)
you can minimize with respect to \(a\) and \(b\) to find your “best fit” line.
minimize(lambda x:((data_ref2-x)**2).sum(),0.4)
fun: 9951.489423144052
hess_inv: array([[5.e-05]])
jac: array([0.])
message: 'Optimization terminated successfully.'
nfev: 8
nit: 2
njev: 4
status: 0
success: True
x: array([0.01305158])
minimize(lambda X:((d1-X[0]*t-X[1]*np.ones(len(t)))**2).sum(),np.array([0.1,0.1]),method='Nelder-Mead', tol=1e-6)['x']
array([ 0.04405392, -0.17318235])
slope1, intercept1
(0.044053980142284774, -0.17318253969528752)
minimize(lambda X:((d2-X[0]*t-X[1]*np.ones(len(t)))**2).sum(),np.array([0.1,0.1]),method='Nelder-Mead', tol=1e-6)['x']
array([0.06501928, 0.11842078])
slope2, intercept2
(0.0650193686177917, 0.11842051937262404)
minimize(lambda X:((d3-X[0]*t-X[1]*np.ones(len(t)))**2).sum(),np.array([0.1,0.1]),method='Nelder-Mead', tol=1e-6)['x']
array([ 0.73878142, -1.35719998])
slope3, intercept3
(0.7387814055506847, -1.3571997755399319)
We see that our minimization procedure is reproducing the linear regression results, pretty close to exactly. However, this does not guarantee that we have a good fit to the data. To see how well we are doing we are going to plot the data vs the best fit line, and also a histogram of our error:
fig_h,ax_h=plt.subplots(figsize=(12,12),ncols=3,nrows=3)
ax_h[0,0].scatter(t,d1)
ax_h[0,0].scatter(t,slope1*t+intercept1)
ax_h[0,1].scatter(t,d2)
ax_h[0,1].scatter(t,slope2*t+intercept2)
ax_h[0,2].scatter(t,d3)
ax_h[0,2].scatter(t,slope3*t+intercept3)
ax_h[1,0].hist(d1-slope1*t-intercept1,bins=20)
ax_h[1,1].hist(d2-slope2*t-intercept2,bins=20)
ax_h[1,2].hist(d3-slope3*t-intercept3,bins=20)
ax_h[2,0].scatter(t,d1-slope1*t-intercept1)
ax_h[2,1].scatter(t,d2-slope2*t-intercept2)
ax_h[2,2].scatter(t,d3-slope3*t-intercept3)
plt.show()
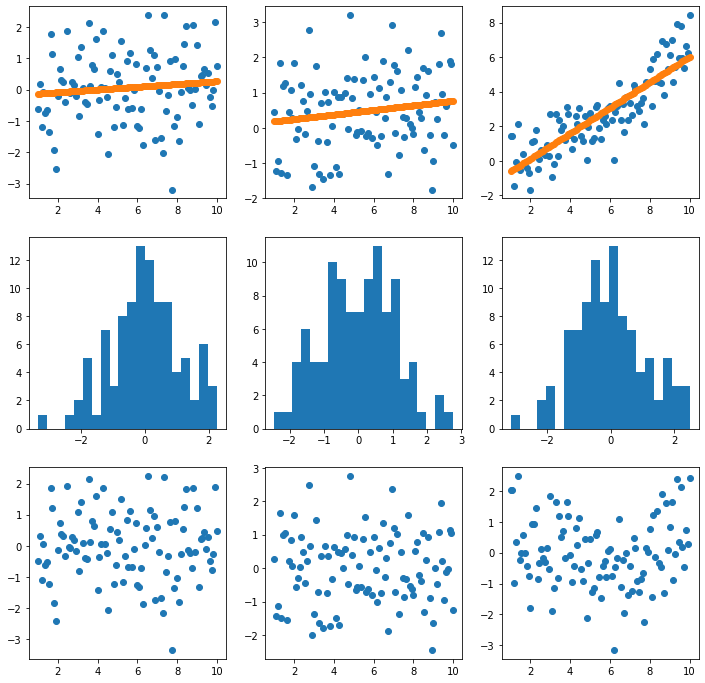
These plots look pretty good. What about the \(\chi^2\) after removing the best fit line:
((d1-slope1*t-intercept1)**2).sum(),((d2-slope2*t-intercept2)**2).sum(),((d3-slope3*t-intercept3)**2).sum()
(123.878341340528, 114.2267169116914, 124.2774840597678)
(d1**2).sum(),(d2**2).sum(),(d3**2).sum()
(125.69249389635905, 139.79811466358296, 1232.430424286052)
At first sight, everything looks fine. Interestingly, not all the data was made with a straight line. The first two, d1 and d2 were, but d3 was actually made with a parabola:
plt.plot(t,slope3*t+intercept3)
plt.plot(t,0.07*t**2)
plt.scatter(t,d3)
<matplotlib.collections.PathCollection at 0x119b10dc0>
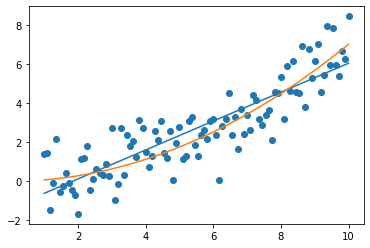
((d3-0.07*t**2)**2).sum()
107.98045329875646
More general \(\chi^2\) minimization#
We can now see that pattern for finding a set of best fit parameters for any model given the data. Suppose with think our signal is described by a model \(S(t; \vec X)\) where \(\vec X\) is a list of parameters decribing the model. Now we caculate
\( \sum (data-S(t;\vec X))^2\)
and we find the minimum in terms of the components of \(X\).
For example, we can add allow our data to be modelled by a parabola instead of just a line as follows:
minimize(lambda X:((d3-X[0]*t**2-X[1]*t-X[2]*np.ones(len(t)))**2).sum(),np.array([0.1,0.1,0.1]),method='Nelder-Mead', tol=1e-6)['x']
array([ 0.06909539, -0.02126793, 0.25711986])
For simple models like this one, this is a relatively straightforward minimization problem: after adding up all the data, we have quadratic polynomial in a small number of variables. However, for more complicated models (and data) finding the minimum can be extremely difficult.
def model(X,n=8):
model=np.zeros(len(t))
for i in range(n):
model+=X[i]*t**i
return model
def g(X,n=8):
return ((d3-model(X,n))**2).sum()
g(0.1*np.ones(8))
9831016539991.152
Xsol=minimize(g,0.1*np.ones(8),method='Nelder-Mead', tol=1e-6)['x']
plt.plot(t,model(Xsol))
plt.scatter(t,d3)
<matplotlib.collections.PathCollection at 0x11df7e2b0>
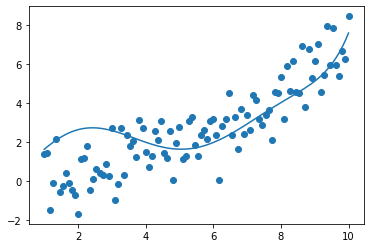
g(Xsol)
223.83679406449997
We will see more advanced strategies for dealing with these kinds of higher dimensional problems. We are really just scratching the surface of an enormous problem - many AI/machine learning techniques boil down to minimizing some nonlinear function of a large number of parameters. In some cases, it is more or less obvious what it is you want to minimize and all the new ideas correspond to better or faster ways to find the minima.
Saving Data#
The final thing you might like to do is to write your own data to a file. Sometimes you do a long calculation and you don’t want to have to recaclulate it every time you want to make a figure, for example.
The most basic form of writing to a file is the opposite of what we did above
f=open("save_data_test.txt","w") # 'w' means writes (over the existing file),
f.write('# here is some preamble\n')
f.write('# here is some more preamble\n')
t=np.linspace(1,10,100)
for i in range(100):
f.write(str(t[i])+',')
for j in range(3):
f.write(str(np.random.randn())+',')
f.write('\n')
f.close()
Often you may want to save something that is already in the form of an array or a python friendly object. There are LOTS of ways to do this (pandas is a popular library with lots of options, pickle is also popular). Hoever, the key idea is always the same: some library has a way of saving and reading a type of object that is pretty fast. E.g. numpy has a save option:
outdata=np.random.randn(100)
with open('save_random.npy', 'wb') as f: # wb means write binary
np.save(f,outdata)
with open('save_random.npy', 'rb') as f: # rb means read binary
a = np.load(f)
a
array([ 2.18066855e-01, 6.81363096e-01, 1.50365211e+00, -2.37433590e-01,
-1.47250604e+00, -1.38024553e-01, 1.42601539e-01, -1.25445736e-01,
-1.91803101e-01, 1.18814606e+00, -6.57773592e-01, 3.05688957e-01,
1.33621127e+00, -2.52876104e+00, -5.39773530e-01, -8.99736563e-01,
7.47054159e-01, -6.89449358e-01, 9.56189847e-02, 2.66292578e+00,
-1.50344143e+00, 3.43407359e-01, -2.79859465e-01, 1.23235657e+00,
-6.37821845e-01, 1.29806123e+00, -1.08391257e-03, 1.49932892e-01,
6.73576463e-01, -4.16760199e-01, -1.58721567e+00, -2.12869273e+00,
7.82318171e-01, 6.04968025e-02, -6.44481389e-01, -3.47925843e-01,
1.11113673e+00, 4.87647255e-01, -7.46142074e-01, -1.81408641e+00,
-6.20179013e-01, -1.91172947e+00, 2.14252877e-02, -1.23278129e+00,
-3.96539443e-01, 8.16497807e-02, -1.22007830e-01, -1.28020464e+00,
7.14807082e-03, -2.58096672e-01, 6.50741807e-01, 4.24963583e-01,
-1.60728146e+00, -5.29992848e-01, 9.01145673e-01, -3.22541871e-01,
4.44312762e-01, -1.21264883e+00, -1.86457926e-01, -9.03679374e-01,
-9.85147378e-02, 3.86307528e-03, -6.30038901e-01, 7.59365365e-01,
1.26302175e+00, 6.81821537e-01, 1.36656971e+00, -2.19540029e+00,
1.47152282e+00, 1.94993392e+00, 4.13096811e-01, -8.68946642e-01,
-4.31682933e-01, 3.90702087e-01, -1.21751508e+00, -2.97026151e-01,
-1.32054845e+00, 8.52185271e-02, -1.18374329e+00, -5.87864047e-01,
2.32895009e-01, 9.94002436e-01, 1.93021376e+00, 1.35646008e-01,
-1.91807686e-03, -9.75260951e-01, -1.51883216e+00, -5.96426413e-01,
1.57621368e+00, -6.63118108e-02, -1.66668051e+00, -1.84721980e+00,
-8.40561800e-02, 1.54372723e+00, 3.82304709e-01, 1.72699323e+00,
1.65520688e+00, -9.99340903e-01, -6.39079302e-01, -1.45894179e-01])
Summary#
We have just started to scratch the surface of how do deal with data. However, we were able to see the most basic problems in data analysis in some relatively simple form: (1) data cleaning - getting your data stored in a useful way, (2) data visulization - understanding what your data represents, (3) data analysis - separating the signal from the noise, (4) store your work for easy use in the future.