Topic 6b: Intro to Machine Learning
Contents
Topic 6b: Intro to Machine Learning#
import numpy as np
import matplotlib.pyplot as plt
Machine learning comes in many forms. However, at its core, machine learning techniques as it is used today is not functionally different than the data analysis we have been doing. The basic idea is the same: I am trying to “learn” how to predict something or do something (make a good model) give past experience (data).
The key difference between scientific data analysis and generic machine learning algorithms is that the goal is not to produce a measurement of a physical parameter with well understood error bars: it is to strategy for making decisions that is “good enough” for the application you have in mind. However, this isn’t always true and machine learning is increasingly employed in scientific domains where the goals are the same.
For the purpose of this class, we will only talk about some fairly basic models of supervised learning. Roughly speaking, this means we have a data set that we will train our model on where we know the true answers.
To make this concrete, we are going to use the IRIS data set from scikitlearn.
from sklearn.datasets import load_iris
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
X, y = load_iris(return_X_y=True)
Here \(X\) is some data about the eye that we are given and we are trying to predict y, one of 3 types of iris shapes
print(X[0:3])
print(y)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
So our goal is to make a function \(f(X) \to y\). We are going to use part of our data to train out model and then the rest to test how it did. This is important because we have good reason to worry about overfitting, so we want to test how well it predicts the result when you don’t have the luxuary of knowing the result already.
Here we will make a training set by using every 5th entry:
Xtrain=X[::5,:]
ytrain=y[::5]
Most basic algorithms are designed to minimize some kind of “cost function” (or kernel). The idea is that when you have a good model, this cost function (whatever it is) will be small.
We will start by using a method that will look quite familiar. We will choose the kernel RBF defined by
where \(d\) is the distance between the two results.
kernel = 1.0 * RBF(1.0)
This method will assign a probability for each of the possible iris types (\(y\)) given the eye measurements \(X\). We can guess that this means there is some \(x'(y)\) for each \(y\) value so thatb \(P(y|X)= k(X,x'(y))\) and the computer is trying to the \(x'(y)\) that maximize the posterior. We can now fit this model as follows:
gpc = GaussianProcessClassifier(kernel=kernel,random_state=0).fit(Xtrain, ytrain)
gpc.score(Xtrain, ytrain)
1.0
Now we can see how we did:
out=gpc.predict_proba(X)
fig,ax=plt.subplots(figsize=(12,12),ncols=2,nrows=2)
ax[0,0].scatter(X[:,0],X[:,1],c=y)
ax[0,0].set_title('Data')
ax[0,1].scatter(X[:,0],X[:,1],c=out)
ax[0,1].set_title('Prediction')
ax[1,0].scatter(X[:,0],X[:,2],c=y)
ax[1,0].set_title('Data')
ax[1,1].scatter(X[:,0],X[:,2],c=out)
ax[1,1].set_title('Prediction')
Text(0.5, 1.0, 'Prediction')
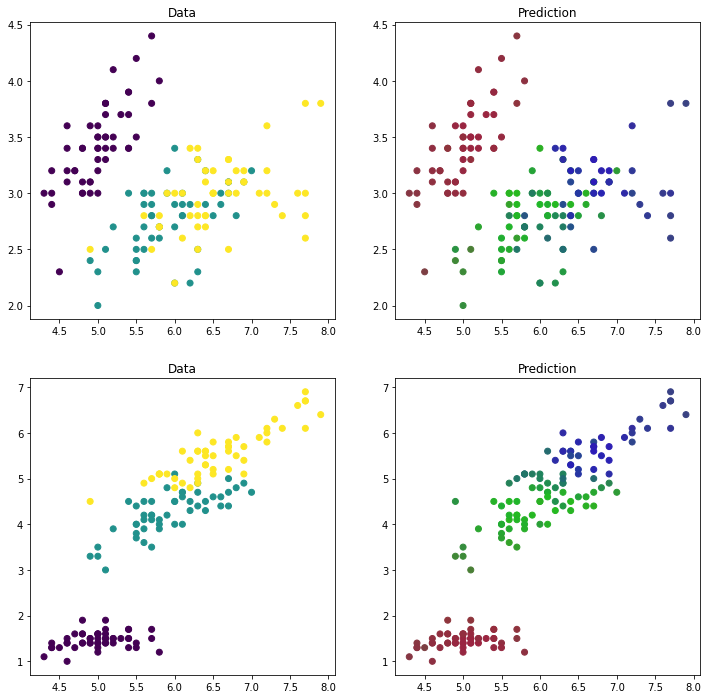
gpc.score(X, y)
0.9133333333333333
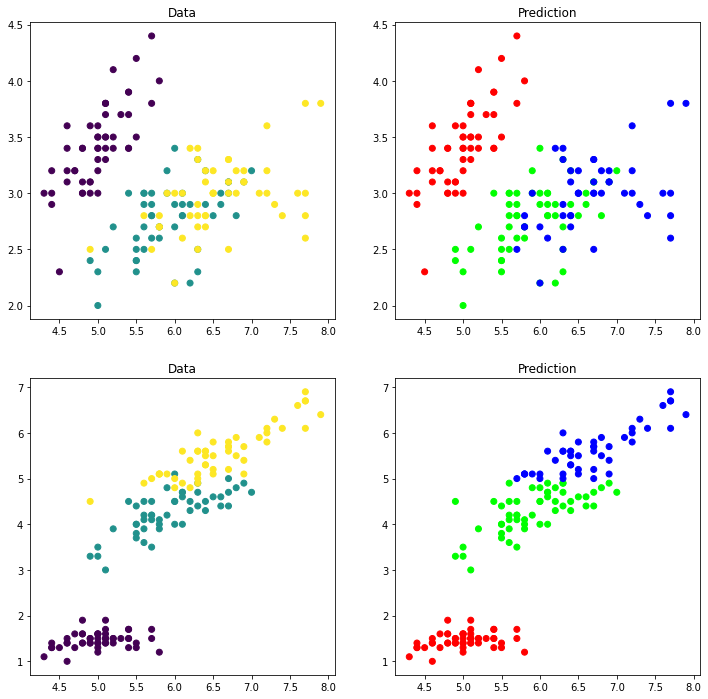
Now we can try again with another function to extremize. Here we will use decision trees. This is a model designed for classifying where essentially the data is split according to simple rules (roughly if X then y). The rules are changed to optimize the predictions on the training set:
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=0)
clf_fit=clf.fit(Xtrain, ytrain)
clf_out=clf_fit.predict_proba(X)
clf_fit.score(X, y)
0.9466666666666667
fig,ax=plt.subplots(figsize=(12,12),ncols=2,nrows=2)
ax[0,0].scatter(X[:,0],X[:,1],c=y)
ax[0,0].set_title('Data')
ax[0,1].scatter(X[:,0],X[:,1],c=clf_out)
ax[0,1].set_title('Prediction')
ax[1,0].scatter(X[:,0],X[:,2],c=y)
ax[1,0].set_title('Data')
ax[1,1].scatter(X[:,0],X[:,2],c=clf_out)
ax[1,1].set_title('Prediction')
Text(0.5, 1.0, 'Prediction')
Take-aways#
At a very surface level there is essentially no difference betweew “machine learning” and our data analysis techniques. Both are attempts to give the best possible model of a data set by finding extremes of a given function.
However, if we think back on our experience solving equations or finding minima / maximima, we recall that the computer could easily get into trouble. Finding minimima is not always easy, especially if you don’t have a good starting place. While all of the focus may sound like it is the choice of the function we are minimizing, the reality is that the real challenge is finding the minimum. As an illustration - suppose I want my ML algorithm to find a solution to a differential equation. I.e. we want to find the function \(x(t)\) that satisfies
However, \(x(t)\) is a function, so finding its value at every point in \(t \in (0, 100)\) requires minimizing over a very large number of parameters (100s or 1000s depending on how finely we need to know \(x(t)\)). In this precise sense, ML / AI is often a name for a rapid method to minimize functions to a given approximation.