Topic 6a: Bayes’ Theorem
Contents
Topic 6a: Bayes’ Theorem#
import numpy as np
import matplotlib.pyplot as plt
We have talked about data analysis thus far with using the word “error bar”. This is a somewhat shocking omision, as data without errors are pretty useless. However, our goal in this course is not just to give you a tool that you don’t understand, but to teach you what the tools are for. Error bars are an extreme example, as they are both the most important part of any scientific analysis and yet are the piece most likely to be wrong.
A good way understand errors and apply them effectively is to think like a Bayesian. The reason is that it puts you and your hypotheses right in the middle of the action so that you can see how your choices matter.
To get us started, this is Bayes’ Theorem:
Where \(P(H|D)\) is the probability of the Hypothesis (\(H\)) given the data (\(D\)) and vise versa for \(P(D|H)\), and \(P(H)\) (\(P(D)\)) is the probability of the hypothesis (data).
I always find this very hard to understand. There are a bunch of variables I don’t know what they mean. So, let’s think about a simple example:
Example: Hit by a Taxi#
You live in a place where the are 85 percent green taxis and 15 percent blue taxis. You got hit by a taxi and a witness claims it was blue. However, it is determined that eye-witness are accurate about 80 percent of the time and mis-identify the color 20 percent of the time.
So the question is “what is the probability you were hit by a blue cab?”. So, our hypothesis (\(H\)) is that we you hit by a blue cab and we want to compute \(P(H|D)\), given the data (\(D\)) that someone saw a blue cab. If we didn’t know the theorem, what would we do? We would say, the probably a blue cab was involved, knowing nothing else is 15 percent (\(P(H) =0.15)\)) and the probably that someone would see a blue cab if it was a blue cab is 80 percent (\(P(D|H) = 0.80\)). The answer is not \(0.15 \times 0.80\) because (1) this makes no sense - even when \(P(D|H) =1\) it gives a small probability and (2) the probabilities of the 2 possibilities don’t add to 1 - \(0.15 \times 0.8 + 0.85 \times 0.2 \neq 1\). To normalize our answer correclty, we need to divide by all the different ways we could arrive at the data, namely \(0.15 \times 0.8 + 0.85 \times 0.2\). So, our answer is
Notice that if if the eye witness is perfect (\(P(D|H) = 1\)), our answer is 1, as it should be.
The probability of the data, \(P(D)\), doesn’t actually depend on the hypothesis: it is a sum over all possibilities. Its role in life is just to make the probability normalized to one. To see this, we note that the only two options are that you got hit by a blue taxi or a green taxi. If we were to now ask “what is the probability you were hit by a green taxi?”, we would have to change \(𝑃(𝐷|𝐻)=0.2\) (there is only a 20% chance that the witness would think it was blue if it was really green) but the probability of the hypothesis itself should \(P(H) = 0.85\) since 85% of taxis are green. But the probability of the data stays the same, since we already enumated all the possibilities. This means that
Notice that now
This is really what Bayes’ theorem is all about: one of the hypotheses must be true, so if \(P(H|D)\) is really a probability, then it must add to up one when we sum over all the possibility. Bayes’ theorem is just reminding us how to do that.
Application: coin flipping#
Suppose we have a coin that gives us heads with probability \(p\) and tails with probability \(1-p\) where \(p \in [0,1]\) is unknown to us. Now I flip the coin \(1000\) times and get \(550\) heads and \(450\) tails. What do you think \(p\) is?
One way to look at it is to simply simulate what happenss with a fair coin as ask it how often you get 550 heads. Let’s try 1000 simulations:
N_sims=1000
heads=np.zeros(N_sims)
for i in range(N_sims):
heads[i]=np.random.randint(2,size=1000).sum()
fig,ax=plt.subplots()
ax.hist(heads,bins=20)
plt.show()
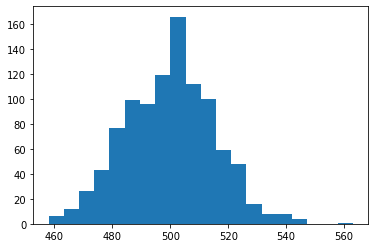
heads.max()
563.0
Getting 550 heads is possible but very unlikely when \(p=1/2\) (a fair coin). Instead, let’s apply the machinary of Bayes:
Let’s say we have \(N\) total flips and get \(n\) heads. The probably of finding \(n\) heads for a given \(p\) gives us the probabability of the data (the likelihood):
where we have the binomial coefficient \(\Big(\frac{N}{n} \Big)\) which accounts for all the possible ways of getting \(n\) heads (e.g. if you get only \(n=1\), it could have been on the first, second…,last flip of the coin).
We have no idea what the probably of the different models is, so we will assume a flat distribution \(P(p) = \) constant. Finally, we need to normalize the result by dividing by the integral over \(p\), such that
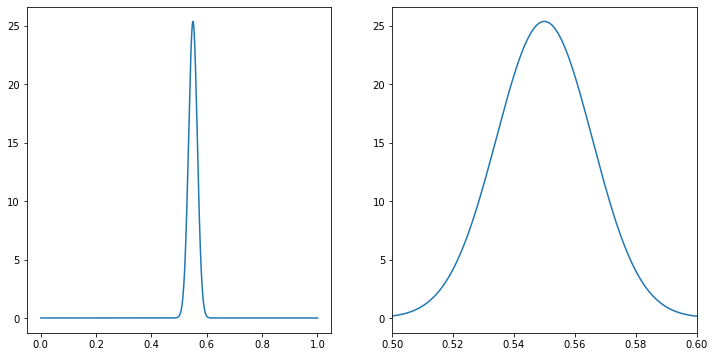
Let’s apply this to \(N=1000\) and \(n=550\):
from scipy import integrate
from scipy import special
integrate.quad(lambda p:p**(550)*(1-p)**(450)*special.binom(1000,500),0,1)
(0.14876167743337448, 4.263789920566359e-09)
p_lin=np.linspace(0,1,1000)
fig,ax=plt.subplots(figsize=(12,6),ncols=2)
ax[0].plot(p_lin,p_lin**(550)*(1-p_lin)**(450)*special.binom(1000,500)/0.14876167743337448)
ax[1].plot(p_lin,p_lin**(550)*(1-p_lin)**(450)*special.binom(1000,500)/0.14876167743337448)
ax[1].set_xlim(0.5,0.6)
(0.5, 0.6)
Note: the binomial coefficients are totally unnecessary but they keep us from multiplying and dividing by very small numbers:
integrate.quad(lambda p:p**(550)*(1-p)**(450),0,1)
(5.505028184578253e-301, 9.11751014007829e-301)
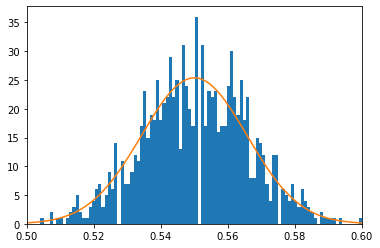
Now we can still compare to simulations. Notice that our distribution is peark at 0.55 =550/1000, so we can simulate \(p=0.55\) and compare to our figure
N_sims=1000
heads_p=np.zeros(N_sims)
for i in range(N_sims):
heads_p[i]=(np.random.rand(1000) < 0.55).sum()/1000.
fig,ax=plt.subplots()
ax.hist(heads_p,bins=100)
ax.plot(p_lin,p_lin**(550)*(1-p_lin)**(450)*special.binom(1000,500)/0.14876167743337448)
ax.set_xlim(0.5,0.6)
(0.5, 0.6)
Gaussian Noise#
Now let us return to our previous discussion of data where we had a deterministic model for the signal and a random source of noise
The noise is drawn from a Gaussian distribution with a standard deviation \(\sigma\).
It is definitely easier to measure \(S(t)\) if we know what \(\sigma\) is ahead of time. But how would we know this? In many cases, we can simply make a measurement when we know there is no signal. E.g. if you cover up a telescope, then the pictures you take are just the noise of your camera. By doing this, we get \(N\) measurements drawn from a Gaussian distribution but we don’t know \(\sigma\). Now we can use our machinary of Bayesian inference to figure it out. For each data point, \(n_i\), the probability of the data, given a \(\sigma\) is
where \(\Delta n\) is accuracy with which I measure the noise, i.e. it is the size of the bins in which we group \(n_i\) since we are not measuring to infinite accuracy.
Let’s assume we know thing about \(\sigma\) so that \(P(\sigma) =\) constant, since \(P(D)\) is also just some constant, we can worry about normalization our result later. Putting this together, we have
We learn wwo things: (1) we recall that \(\sum_i n_i^2 \approx N \bar \sigma^2\) where \(\bar \sigma\) is the true variance. We can make a figure of this function:
from scipy import integrate
s=np.linspace(0.6,1.4,100)
def chiout(s,N,s0=1):
const=integrate.quad(lambda x:np.exp(-N*s0**2/(2*x**2))/(np.sqrt(2*np.pi*x**2)**(N)),0.2,2,limit=10000)
return np.exp(-N*s0**2/(2*s**2))/(np.sqrt(2*np.pi*s**2)**(N))/const[0]
plt.plot(s,chiout(s,20))
plt.plot(s,chiout(s,80))
plt.plot(s,chiout(s,320))
[<matplotlib.lines.Line2D at 0x124a78c10>]
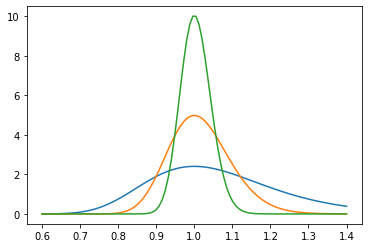
We see that this follows a familiar pattern: when we increase the amount data by a factor of 4, the width of these curves decreases by a factor of two. Said differently our error scales as \(1/\sqrt{N}\)
(2) we can apply this to data for any \(n_i\) and find the maximum \(\sigma\). The maximum likelihood will will not necessarily reproduce the one we used to represent the data, but the likelihood should include a reasonably large probability of the true value.
ni=np.random.randn(30)
def chi_data(s,n_in):
noise2=(n_in**2).sum()
N=len(n_in)
const=integrate.quad(lambda x:np.exp(-noise2/(2*x**2))/(np.sqrt(2*np.pi*x**2)**(N)),0.2,2,limit=10000)
print(const)
return np.exp(-noise2/(2*s**2))/(np.sqrt(2*np.pi*s**2)**(N))/const[0]
for i in range(10):
ni=np.random.randn(50)
plt.plot(s,chi_data(s,ni))
plt.show()
(1.9772318316118098e-30, 5.900949772304313e-31)
(1.4589696220899085e-32, 6.025749243246302e-34)
(2.465019166862211e-29, 9.975462411118002e-31)
(1.2425032236165225e-31, 1.1492744057569535e-33)
(3.141661152531215e-27, 3.882366580117792e-29)
(5.138185559680873e-32, 2.253005235139706e-33)
(3.2578282240532346e-33, 3.4912635409037696e-33)
(1.106442479945211e-33, 2.8791215834606624e-36)
(2.7465603647238282e-30, 8.719924432212726e-31)
(6.075950448116499e-31, 7.722661607520039e-32)
for i in range(10):
ni=np.random.randn(300)
plt.plot(s,chi_data(s,ni))
plt.show()
(2.4623648495548332e-191, 3.6465351583578427e-191)
(1.527943779880697e-185, 2.381499738615619e-185)
(3.991989845053263e-191, 5.942989582789744e-191)
(1.2402218453034474e-182, 1.92145480639164e-182)
(3.420085470345729e-188, 5.357036927008968e-188)
(1.3087239730149391e-195, 1.6486479476206775e-195)
(5.142358822344616e-181, 8.067020020518534e-181)
(1.1646729635124476e-190, 1.7529557450772937e-190)
(5.556106976329461e-178, 8.848993869639526e-178)
(3.522721656511771e-186, 7.654819336488454e-187)
Of course, we know the maximum of this curve will lie at \(\sigma = \sqrt{\sum n_i^2/N}\), so we can also just make a histogram of the maximum likelihood points as
Nsims=1000
Ndata=100
max_list=np.zeros(Nsims)
max_list_h=np.zeros(Nsims)
for i in range(Nsims):
ni=np.random.randn(Ndata)
max_list[i]=np.sqrt((ni**2).sum()/Ndata)
fig,ax=plt.subplots(figsize=(8,6))
ax.hist(max_list,bins=40)
Ndata=400
for i in range(Nsims):
ni=np.random.randn(Ndata)
max_list_h[i]=np.sqrt((ni**2).sum()/Ndata)
ax.hist(max_list_h,bins=40)
plt.show()
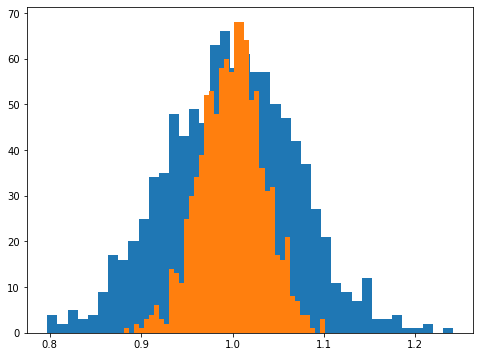
We again see that the width of these histograms scales as \(1/\sqrt{N}\).
Bayesian Inference for the Signal#
Taking enough data with no signal, we can determine \(\sigma\) to good enough accuracy that we will assume it is known. This isn’t always true, but it simplifies how we think about measuring the signal. We return again to our assumption, but now let’s make it clear that our hypothesis is only about the signal:
However, the only thing that is random is the noise, so the probability of the data is simply:
This is literally just the same equation we had before since \(data_i -S_i =n_i\). However, now our posterior is for the parameters of our model, rather than \(\sigma\).
Let’s see how this works for a line with noise:
trange=np.linspace(0,10,1000)
data_t=0.07*trange+np.random.randn(1000)
def Pos_line(data,a,b,t,s=1):
noise2=((data-a*t-b)**2).sum()
return np.exp(-noise2/(2*s**2))
a_r=np.linspace(0,0.12,100)
Pos_r=np.zeros(100)
for i in range(100):
Pos_r[i]=Pos_line(data_t,a_r[i],0,trange)
plt.plot(a_r,Pos_r)
plt.show()
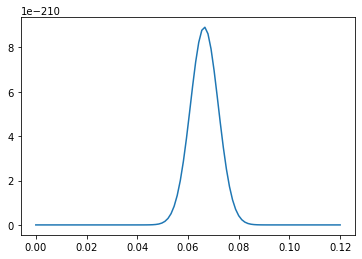
We notice the very small size of the posterior here, because I didn’t bother to normal by dividing by \(P(D)\). In practice, we we need to know about the postior is just the maximum likelihood point and \(1\sigma\), \(2\sigma\), \(3\sigma\) lines. However for this we don’t actually need to work with the full posterior. Instead we can take the log:
We see that minimizing \(-\log P(H,D)\) is exactly the same quantity we minimized in finding our best fit curves. Now suppose that in the vacinity of the maximum likelihood point for a parameter of our model, \(a\) we have
Then when \(a = a_{\rm min} + n \sigma_a\) we have \(-2\log P(H,D) = -2\log P(H,D)|_{a_{\rm min}}+ n^2\)
def chi_line(data,a,b,t,s=1):
noise2=((data-a*t-b)**2).sum()
return noise2/(s**2)
chi_r=np.zeros(100)
for i in range(100):
chi_r[i]=chi_line(data_t,a_r[i],0,trange)
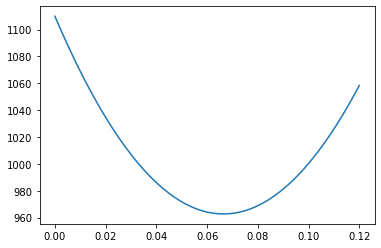
plt.plot(a_r,chi_r)
plt.show()
from scipy.optimize import minimize
from scipy.optimize import newton
a_min_loc=minimize(lambda x:chi_line(data_t,x,0,trange),0.070)['x']
minimize(lambda x:chi_line(data_t,x,0,trange),0.070)
fun: 962.7113508750148
hess_inv: array([[1.49924965e-05]])
jac: array([7.62939453e-06])
message: 'Optimization terminated successfully.'
nfev: 30
nit: 2
njev: 15
status: 0
success: True
x: array([0.066442])
Having found the location of the minimum, we now proceed to find the value of the minimum and the location of the \(1\sigma\) and \(2\sigma\) contours:
chi_min=chi_line(data_t,a_min_loc,0,trange)
Pos_max=Pos_line(data_t,a_min_loc,0,trange)
print(chi_min,Pos_max)
962.7113508750148 8.910176863112389e-210
The \(1\sigma\) lines are the minimum \(\chi^2 +1\)
s1L=newton(lambda x:chi_line(data_t,x,0,trange)-chi_min-1,0.065)
print(s1L)
0.06096615168467038
s1R=newton(lambda x:chi_line(data_t,x,0,trange)-chi_min-1,0.08)
print(s1R)
0.07191786250924656
The \(2\sigma\) lines are the minimum \(\chi^2 +2\)
s2L=newton(lambda x:chi_line(data_t,x,0,trange)-chi_min-4,0.065)
print(s2L)
0.05549029627238202
s2R=newton(lambda x:chi_line(data_t,x,0,trange)-chi_min-4,0.08)
print(s2R)
0.07739371792153234
chi_min
962.7113508750148
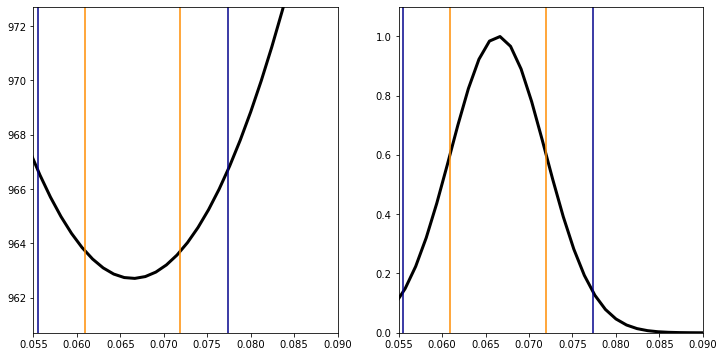
fig,ax=plt.subplots(figsize=(12,6),ncols=2)
ax[0].plot(a_r,chi_r,lw=3,color='black')
ax[0].plot(s1L*np.ones(2),[chi_min-2,chi_min+10],color='darkorange')
ax[0].plot(s1R*np.ones(2),[chi_min-2,chi_min+10],color='darkorange')
ax[0].plot(s2L*np.ones(2),[chi_min-2,chi_min+10],color='darkblue')
ax[0].plot(s2R*np.ones(2),[chi_min-2,chi_min+10],color='darkblue')
ax[0].set_xlim(0.055,0.09)
ax[0].set_ylim(chi_min-2,chi_min+10)
ax[1].plot(a_r,Pos_r/Pos_max,lw=3,color='black')
ax[1].plot(s1L*np.ones(2),[0,1.1],color='darkorange')
ax[1].plot(s1R*np.ones(2),[0,1.1],color='darkorange')
ax[1].plot(s2L*np.ones(2),[0,1.1],color='darkblue')
ax[1].plot(s2R*np.ones(2),[0,1.1],color='darkblue')
ax[1].set_xlim(0.055,0.09)
ax[1].set_ylim(0,1.1)
plt.show()
print(a_min_loc-s1L,s1R-a_min_loc)
print(a_min_loc)
[0.00547585] [0.00547586]
[0.066442]
At \(1\sigma\), we have determined that \(a = a_{\rm min} \pm 0.0055\)
Now, our line is really a two dimensional space, not a one dimensional space. In this case we have two options: (1) we want to know the multi-dimensional behavior (make a contour plot) or (2) we average over a parameter we don’t care about (marginalize).
First, let us repeat what we did above but now using the model \(S(t|a,b)= a t+b\). First we find the minimum
minimize(lambda X:chi_line(data_t,X[0],X[1],trange),[0.07,0],method='Nelder-Mead',tol=1e-6)
final_simplex: (array([[0.06382864, 0.01743157],
[0.06382843, 0.01743235],
[0.06382857, 0.01743085]]), array([962.6352751, 962.6352751, 962.6352751]))
fun: 962.6352750973032
message: 'Optimization terminated successfully.'
nfev: 83
nit: 43
status: 0
success: True
x: array([0.06382864, 0.01743157])
line_sol=minimize(lambda X:chi_line(data_t,X[0],X[1],trange),[0.07,0],method='Nelder-Mead',tol=1e-6)['x']
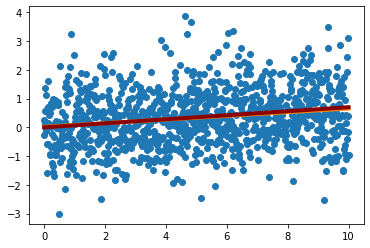
It might seem a bit surprising that when we fit the line, the best fit value of \(a\) is quite far from our best fit result. Concretely, when we set \(b=0\), we got \(a\sim 0.07 \pm 0.055\) and now our best fit \(a\) looks like it is more than 2\(\sigma\) off. We can check that the line is a good fit to the data
plt.scatter(trange,data_t)
plt.plot(trange,line_sol[0]*trange+line_sol[1],lw=4,color='darkorange')
plt.plot(trange,0.07*trange,lw=4,color='darkred')
plt.show()
Now let’s understand what is going on by making a figure of the 2D posterior.
chi_min_line=chi_line(data_t,line_sol[0],line_sol[1],trange)
print(chi_min_line)
962.6352750973032
b_r=np.linspace(-0.5,0.5,100)
A,B=np.meshgrid(a_r,b_r)
logP=np.zeros(A.shape)
for i in range(100):
for j in range(100):
logP[i,j]=chi_line(data_t,A[i,j],B[i,j],trange)
In order to choose contours, we need to know the values of \(\chi^2\) that correspond the 1\(\sigma\) (~68%) and \(2\sigma\)(~95%) confidence regions (i.e. you have the same probability of finding the true mode there as if it was a \(1\sigma\) or \(2\sigma\) line for a Gaussian. For a 2 dimensional space, the answer is 2.3 and 6.18 so we make the contours as:
fig,ax=plt.subplots(figsize=(12,8))
ax.contour(A,B,logP,cmap='RdBu',levels=[chi_min_line+2.30,chi_min_line+6.18])
ax.scatter(0.07,0,marker='x',s=100,color='darkred')
ax.plot(s1L*np.ones(len(b_r)),b_r,color='darkorange')
ax.plot(s1R*np.ones(len(b_r)),b_r,color='darkorange')
ax.plot(s2L*np.ones(len(b_r)),b_r,color='darkblue')
ax.plot(s2R*np.ones(len(b_r)),b_r,color='darkblue')
plt.show()

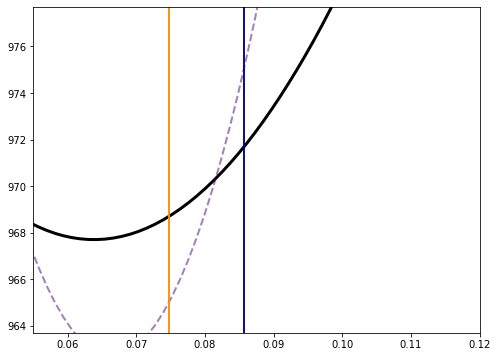
This figure reveals that it is pretty hard to tell apart \(a\) and \(b\). When we include the possibility of \(b\neq 0\), we see that the allowed values of \(a\) cover a much larger region compared to the lines that show the 1\(\sigma\) and 2\(\sigma\) lines we found when \(b=0\).
We can also look at this in terms of the posterior for \(a\) ignoring \(b\). Rather than a conditional probability for the pair \((a,b)\) we just want to know the probability of \(a\) including all possible \(b\) values.
We can think of this like we are flipping a pair of coins and we want to count how often they match. We have to add up all the cases where you get two heads or two tails, even though we know they are different. We are doing the same here, we are going to add up all pairs of \((a,b)\) that have the same value of \(a\):
def chi_marg(data,a,t,s=1):
Mar_pos=integrate.quad(lambda x: Pos_line(data,a,x,t,s=1),-1,1)[0]
return -2*np.log(Mar_pos)
chi_marg(data_t,0.07,trange)
968.0231845387577
chi_mar_out=np.zeros(len(a_r))
for i in range(len(a_r)):
chi_mar_out[i]=chi_marg(data_t,a_r[i],trange)
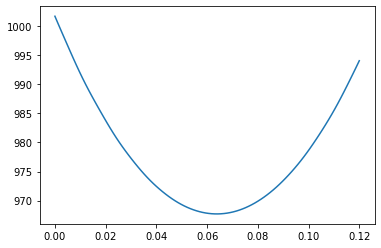
plt.plot(a_r,chi_mar_out)
[<matplotlib.lines.Line2D at 0x12465d550>]
a_min_marg=minimize(lambda x:chi_marg(data_t,x,trange),0.080,method='Nelder-Mead',tol=1e-6)['x']
chi_min_marg=chi_marg(data_t,a_min_marg,trange)
s1L_marg=newton(lambda x:chi_marg(data_t,x,trange)-chi_min_marg-1,0.07)
print(s1L_marg)
s1R_marg=newton(lambda x:chi_marg(data_t,x,trange)-chi_min_marg-1,0.09)
print(s1R_marg)
s2L_marg=newton(lambda x:chi_marg(data_t,x,trange)-chi_min_marg-4,0.07)
print(s2L_marg)
s2R_marg=newton(lambda x:chi_marg(data_t,x,trange)-chi_min_marg-4,0.09)
print(s2R_marg)
0.07477275865175875
0.07477275865180118
0.0857197322433224
0.08571973224332423
fig,ax=plt.subplots(figsize=(8,6))
ax.plot(a_r,chi_mar_out,lw=3,color='black')
ax.plot(a_r,chi_r,lw=2,color='indigo',ls='--',alpha=0.5)
ax.plot(s1L_marg*np.ones(2),[chi_min_marg-4,chi_min_marg+10],color='darkorange')
ax.plot(s1R_marg*np.ones(2),[chi_min_marg-4,chi_min_marg+10],color='darkorange')
ax.plot(s2L_marg*np.ones(2),[chi_min_marg-4,chi_min_marg+10],color='darkblue')
ax.plot(s2R_marg*np.ones(2),[chi_min_marg-4,chi_min_marg+10],color='darkblue')
ax.set_xlim(0.055,0.12)
ax.set_ylim(chi_min_marg-4,chi_min_marg+10)
(963.7051350296721, 977.7051350296721)
Generalizations#
Priors Notice that the marginalized likelihood is much wider than the one where \(b=0\). This makes sense, because forcing \(b=0\) is some kind of extra knowledge we used.
We can make sense of this using the idea of a prior, \(P(H)\). Specifically, the two extremes we have considered are just limits of the prior
When \(\sigma_b \to 0\), we recover the case where \(b=0\) and when \(\sigma_b \to \infty\) we recover a flat prior on \(b\).
def chi_marg_prior(data,a,t,s=1,b=0,sb=1):
Mar_pos=integrate.quad(lambda x: Pos_line(data,a,x,t,s=1)*np.exp(-(x-b)**2/(2*sb**2))/(np.sqrt(2*np.pi*sb**2)),-2,2,epsabs=1.49e-16, epsrel=1.49e-16, limit=10000)[0]
return -2*np.log(Mar_pos)
chi_prior={}
sig_b=[0.3,0.1,0.03,0.01]
for s in sig_b:
chi_prior[s]=np.zeros(len(a_r))
for i in range(len(a_r)):
for s in sig_b:
chi_prior[s][i]=chi_marg_prior(data_t,a_r[i],trange,sb=s)
fig,ax=plt.subplots(figsize=(8,6))
for s in sig_b:
ax.plot(a_r,chi_prior[s],label=str(s))
ax.plot(a_r,chi_r,ls='--')
ax.legend()
plt.show()
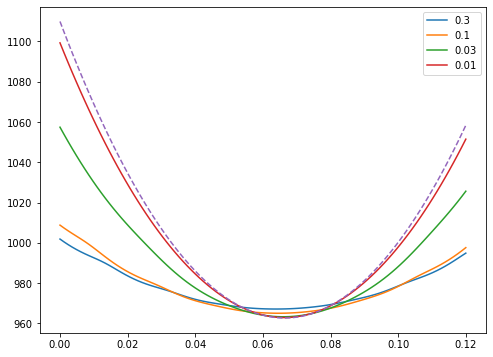
We see in this way what priors are doing for us: they are making it clear how to go between modes with more parameters and less parameters. Reducing the number of parameters is an extreme version of adding information about parameters in the form of a prior.
However, as we will see in the next topic, there is a reason we don’t just add models with lots of parameters and lots of priors when we don’t need to: this integral to marginalize of \(b\) becomes very challenging very quickly.
Non-uniform Errors So far we have been treating the error (std deviation of the noise) \(\sigma\) as constant. When doing this, we saw that finding the maximum value of the posterior was the same the least squares fit that is typical of linear regression algorithms.
However, it is not true that the error in most data is uniform. For example, we might want to combine data taken at different times or with different detectors where the noise. However, in many of these cases, we still understand the noise well enough to treak \(\sigma\) as a known quantity.
We can easily adjust our model to include this option
def chi_line_s(data,a,b,t,s=1):
noise2=((data-a*t-b)**2/(s**2)).sum()
return noise2
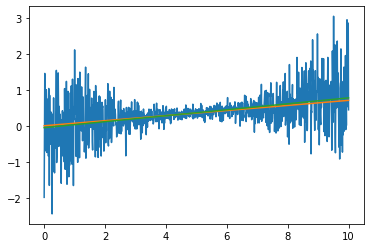
This still has \(s=1\) as a default, but let’s put in \(s\) is a decreasing function of time for both the data and our chi
data_s=0.07*trange+np.random.randn(1000)*(0.1+(trange-5)**2/25)
s_r=(0.1+(trange-5)**2/25)
chi_line_s(data_s,0.07,0,trange,s=s_r)
960.7527714706566
a_min_loc_s=minimize(lambda X:chi_line_s(data_s,X[0],X[1],trange,s=s_r),[0.070,0])['x']
a_min_loc_wrong=minimize(lambda X:chi_line(data_s,X[0],X[1],trange),[0.070,0])['x']
plt.plot(trange,data_s)
plt.plot(trange,a_min_loc_s[0]*trange+a_min_loc_s[1])
plt.plot(trange,a_min_loc_wrong[0]*trange+a_min_loc_wrong[1])
plt
<module 'matplotlib.pyplot' from '/opt/anaconda3/lib/python3.9/site-packages/matplotlib/pyplot.py'>
a_min_loc_wrong,a_min_loc_s
(array([ 0.08267493, -0.05158584]), array([7.05692100e-02, 9.27734236e-05]))
Although the lines look similar, we see that weighting the data with the correct noise model gave a much better fit in terms of being much close to the true value. Furthermore, we also know that it would make no sense to report undercertainties on our least squares fit, as the errors only make sense when you know \(\sigma(t)\).
Summary#
Bayesian inference is argueably the most important framework in which to understand data, whether scientific or otherwise. With very little work, we could understand a lot of seemingly complicated statistical tools as just examples of Bayes’ theorem in special cases. Most important, the concept of uncertainty is essential when trying to understand the world: our knownledge isn’t binary, but comes with levels of confidence. Bayes’ tells us how to make that uncertainty precise and do work for us.